AI Engineer 知识地图 2026
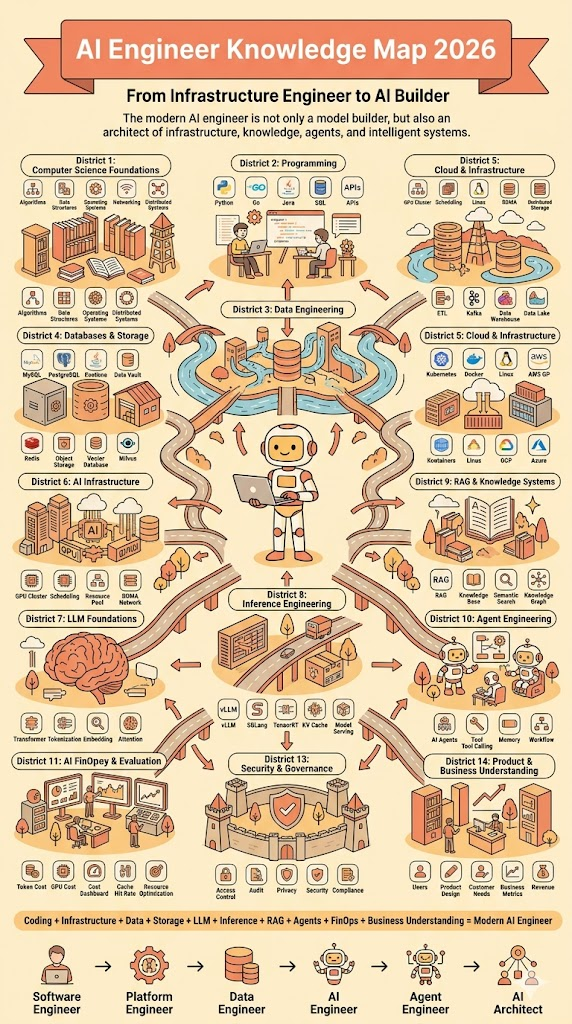
这张图最有价值的地方,不是把 AI Engineer 画成一个“什么都要会”的超人,而是提醒我们:2026 年的 AI 工程能力,已经从“会调一个模型 API”扩展成了一条完整生产链路。你可以不精通每一个区块,但你最好知道每一块在系统里为什么存在。
出处与延伸阅读:
- 本文配图来自用户提供的《AI Engineer Knowledge Map 2026》。
- 相关站内文章:099 Agent Runtime、100 Agent 安全与权限模型、101 Real-World Evals、102 模型路由、103 Embodied AI 与机器人
这篇文章会讲什么
图里把 AI Engineer 的能力拆成了很多“district”:计算机基础、编程、数据工程、数据库、云与基础设施、AI 基础设施、LLM 基础、推理工程、RAG、Agent、安全治理、FinOps、产品与业务理解。
如果逐项展开,很容易写成一张巨大的技能清单,最后只剩焦虑。
我更想把它整理成一个问题:
现代 AI Engineer 到底是在构建什么?
我的答案是:他不是在“写 prompt”,也不是在“接模型”。他在构建一个能把数据、模型、工具、权限、评测和业务目标连起来的智能系统。
先说结论
- AI Engineer 不是传统后端工程师加一点 prompt。它更像基础设施、数据、LLM、产品和运维能力的交叉角色
- 这张图可以压缩成 6 层:工程基础、数据层、模型层、推理与成本层、Agent 与知识系统层、安全评测与业务层
- 不是每个人都要全栈精通。但每个 AI Engineer 至少要知道链路里每一层的失败方式
- 2026 年最重要的分水岭是生产化:能 demo 已经不稀缺,能稳定、便宜、可审计地跑才稀缺
- 长期方向不是“AI Engineer 替代 Software Engineer”。更像是 Software Engineer、Platform Engineer、Data Engineer、ML Engineer 之间长出一个新交叉区
1. 第一层:工程基础,不浪漫但决定下限
图的左上角从计算机基础和编程开始,这很对。
AI 工程听起来很新,但很多失败仍然是老问题:
- 网络超时
- 队列堆积
- 数据库慢查询
- 缓存击穿
- 权限配置错
- 日志打不出来
- 部署回滚不了
- 任务状态丢了
模型再强,也救不了一个没有工程地基的系统。
1.1 为什么计算机基础仍然重要
AI 应用的很多瓶颈并不在模型,而在系统:
- 长上下文请求为什么慢
- 多个工具调用为什么会互相阻塞
- 流式输出为什么会卡
- 向量检索为什么偶尔召回不到
- Agent 跑到第 20 步为什么状态乱了
- 同一个请求为什么成本忽高忽低
这些问题最后都回到操作系统、网络、分布式系统、数据库、缓存、队列、观测性。
所以 AI Engineer 的第一条线不是“会不会写漂亮 prompt”,而是能不能把一个会调用模型的系统做成可靠服务。
1.2 编程语言不神圣,工程习惯更重要
图里列了 Python、Go、Java、SQL、API 等。实际工作里,语言不是最关键的分界线。
更重要的是:
- 会不会写清楚的接口
- 会不会把任务拆成可测试模块
- 会不会处理重试、幂等、超时和取消
- 会不会把错误暴露给人看
- 会不会把配置、密钥和权限分开管理
AI 系统比传统系统更需要这些习惯,因为模型输出天然不稳定。工程边界越松,模型的不稳定就越容易扩散。
2. 第二层:数据层,决定模型知道什么
图的中心是 Data Engineering,这个位置很合理。
很多 AI 产品的问题,表面上是“模型答错了”,背后其实是数据层出了问题:
- 文档没有同步
- 字段语义不一致
- 权限数据混在一起
- embedding 用了过期内容
- 检索结果没有版本
- 业务指标口径不同
- 数据湖里有,但应用拿不到
模型不会自动理解你公司的真实状态。它看到什么,取决于你把哪些数据、以什么格式、在什么权限下交给它。
2.1 Data Engineer 和 AI Engineer 的交界
传统 Data Engineer 关心的是 ETL、仓库、湖、流处理、质量校验。AI Engineer 也需要这些,但关注点会多一层:
| 数据问题 | AI 系统里的后果 |
|---|---|
| 字段缺失 | Agent 做错判断 |
| 数据延迟 | 回答过时 |
| 权限混乱 | RAG 泄露信息 |
| 文档重复 | 检索结果互相打架 |
| schema 不稳定 | 工具调用失败 |
| 没有 lineage | 答案无法追溯 |
所以 AI Engineer 不一定要亲自维护所有数据管线,但必须懂数据质量会怎样变成模型质量。
2.2 数据库和存储不是背景板
图里把 MySQL、PostgreSQL、Redis、对象存储、向量数据库、Milvus 等列成单独区块,也很实际。
AI 应用里常见几种存储:
- 关系数据库:用户、权限、业务状态
- 对象存储:PDF、图片、录音、原始文件
- 缓存:会话状态、模型结果、检索片段
- 向量数据库:语义检索
- 搜索引擎:关键词、过滤、排序
- 数据湖/仓库:分析和离线评估
真正的系统往往不是“一个向量库解决一切”,而是多种存储一起工作。
3. 第三层:模型层,别只盯排行榜
图里有 LLM Foundations,也有 Inference Engineering。这个拆分很关键。
会用模型,和会把模型跑进生产,是两件事。
3.1 LLM 基础要懂到什么程度
AI Engineer 不一定要能从零训练 foundation model,但至少要理解:
- tokenization 会怎样影响成本和上下文
- attention 为什么和上下文长度有关
- embedding 为什么适合语义相似,不等于事实正确
- fine-tuning 解决什么,不解决什么
- multimodal 模型看到的图片/视频不是“真实世界”,而是压缩后的表示
- reasoning 模型为什么慢、贵,但在复杂任务上有价值
这些基础不是考试题,而是选型和 debug 的工具。
例如:一个 RAG 系统答错了,你要判断是模型幻觉、检索召回、chunk 切分、权限过滤,还是 query rewrite 出错。没有 LLM 基础,很容易只会“换个更强模型试试”。
3.2 推理工程是 2026 年的硬技能
推理工程包括:
- 模型部署
- batch / streaming
- KV cache
- prompt caching
- 路由和 fallback
- quantization
- GPU 利用率
- 延迟和吞吐
- 成本归因
这和 102 模型路由 是一条线:不是所有任务都该用同一个模型,也不是所有请求都该走最高规格推理。
很多 AI 产品最后不是死在“模型不够聪明”,而是死在:
- 太慢
- 太贵
- 峰值扛不住
- 用户等不起
- 成本算不清
推理工程就是把“能回答”变成“能规模化回答”。
4. 第四层:知识系统和 RAG,让模型接上真实世界
图右侧的 RAG & Knowledge Systems 是 AI Engineer 走向真实应用的关键区块。
RAG 不是“把文档塞进向量库”这么简单。一个能长期维护的知识系统至少要回答:
- 文档从哪里来
- 谁能看
- 多久更新一次
- 怎么切分
- 怎么召回
- 怎么排序
- 怎么引用来源
- 怎么处理冲突信息
- 怎么删除过期知识
- 怎么评估回答质量
这和 085 LLM Wiki 入门 到 094 LLM Wiki 项目 那组文章是相通的:知识不是静态文件夹,而是一套需要持续维护的系统。
4.1 RAG 的成熟标志
一个 RAG 系统比较成熟时,通常会有这些特征:
| 能力 | 说明 |
|---|---|
| 权限感知检索 | 用户只能召回自己有权看的内容 |
| 来源引用 | 答案能回到原文 |
| 混合检索 | keyword + vector + filter 一起用 |
| rerank | 不把第一轮召回直接交给模型 |
| freshness | 能处理文档更新和过期 |
| eval | 有固定问题集和人工/自动评分 |
| feedback loop | 用户纠错能回到知识库维护流程 |
如果这些都没有,只是“embedding + chat”,那还停留在 demo 阶段。
5. 第五层:Agent Engineering,让系统开始行动
图的右下角是 Agent Engineering:AI Agents、Tool Calling、Memory、Workflow。
这正好接上 099 Agent Runtime:
Agent 不是一个更会聊天的模型,而是一个会在约束里执行任务的系统。
5.1 Agent Engineer 关心什么
一个 Agent Engineer 每天真正要处理的,不是“让模型更像人”,而是这些问题:
- 任务怎么拆
- 工具怎么注册
- 工具结果是否可信
- 失败后怎么重试
- 什么时候停
- 哪些动作要确认
- 如何恢复上下文
- 如何记录每一步
- 如何验证任务完成
- 如何防止越权
这就是为什么 Agent Engineering 和 Workflow、Memory、安全、评测放在一起看才完整。
5.2 Memory 不是越多越好
图里把 Memory 放在 Agent 区块里,很容易让人误解成“AI Engineer 要给所有 Agent 加长期记忆”。
我的看法更保守:记忆是一种权限和治理能力,不是装饰。
很多任务只需要短期任务状态:
- 当前目标
- 已经调用过哪些工具
- 哪些结果有效
- 哪些尝试失败
- 下一步计划
长期记忆只有在用户明确授权、价值清楚、可删除、可审计时才值得上。否则它很容易变成隐私风险和错误积累器。
6. 第六层:安全、评测、FinOps、业务理解,决定能不能上线
图底部把 AI FinOps & Evaluation、Security & Governance、Product & Business Understanding 放在一起,我很喜欢这个位置。
因为这些东西不在系统最炫的地方,却决定系统能不能真的进公司。
6.1 安全与治理
100 Agent 安全与权限模型 已经讲过,Agent 安全不能只靠 prompt。
AI Engineer 至少要懂:
- prompt injection
- tool permission
- 数据权限
- 审计日志
- PII 脱敏
- secret 管理
- 模型输出过滤
- MCP server 可信度
- 高危动作确认
越靠近真实业务,安全越不是“上线前检查一下”,而是系统架构的一部分。
6.2 Evaluation
101 Real-World Evals 里说过,公开 benchmark 只能当门槛。真正的 AI Engineer 要会设计自己的评测:
- 真实任务样本
- 人类基线
- 失败分类
- 成本指标
- 安全 case
- 回归集
- 上线前后对比
没有 eval 的 AI 产品,本质上是在凭感觉发版。
6.3 FinOps
AI FinOps 是很多团队低估的部分。
传统云成本主要看 CPU、存储、网络;AI 成本还要看:
- token
- cache 命中率
- 推理模型等级
- 工具调用轮次
- retry 次数
- embedding 重算
- rerank 成本
- GPU 空转
- 长任务失败浪费
如果这些账算不清,产品越成功,成本越吓人。
6.4 产品和业务理解
图的右下角有 Product & Business Understanding。很多工程师会觉得这块“不够技术”,但它其实决定 AI 系统有没有方向。
AI Engineer 需要问:
- 这个 Agent 替用户省的是哪段时间
- 用户愿不愿意信它
- 哪些错误可以接受,哪些不行
- 人在回路应该放在哪里
- 成功指标是自动化率、满意度、收入,还是风险降低
- 成本和价值是否匹配
不会问这些问题,就容易做出很酷但没人敢用的系统。
7. 这张图可以怎么学习
如果把图当成学习路线,我不建议从 14 个 district 逐个打卡。更好的顺序是按“能做出东西”来学。
阶段 1:Software Engineer → Platform Engineer
先把普通工程底子打牢:
- 编程语言
- API 设计
- SQL
- 缓存
- 队列
- Docker
- CI/CD
- 日志和监控
目标不是“懂 AI”,而是能把服务跑稳。
阶段 2:Platform Engineer → Data Engineer
再补数据能力:
- ETL / ELT
- schema 设计
- 数据质量
- 数据权限
- 搜索和索引
- 向量检索
- 文档处理
目标是让模型接到可信、可追溯、可更新的数据。
阶段 3:Data Engineer → AI Engineer
进入模型和应用:
- prompt / structured output
- RAG
- embedding / rerank
- model routing
- inference cost
- eval harness
- observability
目标是做出可评估、可维护的 AI 功能,而不是一次性 demo。
阶段 4:AI Engineer → Agent Engineer
开始处理行动系统:
- tool calling
- workflow
- memory
- sandbox
- approval
- long-running task
- failure recovery
- agent trace
目标是让 AI 不只是回答,而是在边界内完成任务。
阶段 5:Agent Engineer → AI Architect
最后才是架构层:
- 多模型系统
- 企业权限体系
- MCP / A2A
- 私有 eval 平台
- AI FinOps
- 安全治理
- 组织级工作流改造
这个阶段的核心不是“更会写代码”,而是能设计一套多人、多模型、多系统长期运行的 AI 生产体系。
8. 几个容易误读的地方
8.1 “AI Engineer 必须全都会”
不现实,也没必要。
更合理的是 T 型能力:
- 横向知道完整链路
- 纵向在一到两个方向很强
比如有人偏 RAG 和知识系统,有人偏推理和成本,有人偏 Agent Runtime,有人偏安全治理。
真正危险的是只懂自己那一小块,完全不知道上下游怎么失败。
8.2 “会用 AI 工具就是 AI Engineer”
会用 Cursor、Claude Code、ChatGPT 很重要,但这只是生产力工具,不等于工程能力。
AI Engineer 的核心不是“我自己更快”,而是“我能构建一个让系统、团队、用户都更快的 AI 能力”。
8.3 “AI Engineer 会替代所有工程角色”
更可能发生的是角色重新组合。
未来团队里会有:
- 继续深耕平台的 Platform Engineer
- 深耕数据的 Data Engineer
- 深耕模型的 ML Engineer
- 深耕产品体验的 AI Product Engineer
- 把这些层连接起来的 AI Engineer / AI Architect
AI Engineer 不是吞掉所有人,而是在空白处补上连接能力。
9. 和前几篇文章的关系
这篇可以看成前面几篇的总览图:
- 099 Agent Runtime:解释 Agent 能跑起来需要什么工程底座
- 100 Agent 安全与权限模型:解释工具、权限、外部内容和沙箱怎么治理
- 101 Real-World Evals:解释为什么真实任务评测比刷榜更重要
- 102 模型路由 2026:解释多模型系统为什么会成为常态
- 103 Embodied AI 与机器人:解释 Agent 从数字世界走向物理世界时会遇到什么
- 105 AI Control:解释高自治 Agent 为什么需要内部威胁式治理
- 106 AI Cyber Defense:解释 AI 进入漏洞发现和补丁流程后,安全工程怎么变化
图里的每个 district 都能展开成一篇文章,但更重要的是看到它们之间的关系:数据喂给模型,模型通过推理系统运行,RAG 让它接上知识,Agent 让它行动,安全和评测决定它能不能上线,业务理解决定它值不值得做。
小结
这张《AI Engineer Knowledge Map 2026》可以浓缩成一句话:
现代 AI Engineer 的核心能力,是把“智能”接进真实系统。
这件事需要模型知识,但不止模型;需要基础设施,但不止基础设施;需要数据,但不止数据;需要产品感,但不能只靠产品感。
如果你从传统软件工程转过来,不要被图吓到。最稳的路线不是把每个图标都学一遍,而是沿着一条真实系统链路往前走:
服务能跑稳
→ 数据能接准
→ 模型能用对
→ 知识能更新
→ Agent 能行动
→ 权限能收住
→ 结果能评估
→ 成本能算清
→ 业务能闭环走到这里,你就不只是“会用 AI 的工程师”。
你开始接近一个真正的 AI Builder。